R-CNN 논문 리뷰는 지난 포스팅을 참고하길 바란다: https://hyelimkungkung.tistory.com/25
Rich feature hierarchies for accurate object detection and semantic segmentation
Rich feature hierarchies for accurate object detection and semantic segmentation 늘 느끼는 거지만... 말로 이해한 걸 표현하는 건 너무 어렵다 말로 느끼는 걸 표현하는 건 쉬운데 이해한 걸 표현하기는 어..
hyelimkungkung.tistory.com
프로젝트 개요
(0) 서론, 데이터 셋 소개: https://hyelimkungkung.tistory.com/27
(1) selective serarch: https://hyelimkungkung.tistory.com/28?category=935193
(2) fine tuning: https://hyelimkungkung.tistory.com/29
(3) linear svm, (4) 결론: https://hyelimkungkung.tistory.com/30
0 서론, 데이터 셋 소개
이번 포스팅에서는 저번에 이해한 것을 바탕으로 차근차근 구현해보기로 했다. 다만 저번에 했던 프로젝트, 꽃 사진 분류기'는 정말 재미삼아서 해 본 거였으니 이번에는 좀 그럴싸한 주제로 해보기로 했다. 후 그래서 너무 어렵다.
따라서 본 프로젝트의 주제는 'blood cell 사진을 통해서 혈액 세포를 분류'하기 였다. 프로젝트의 데이터 셋은 https://public.roboflow.com/object-detection/bccd 여기서 따왔다.
* roboflow에 괜찮은 데이터 셋이 많다. 프로젝트는 해보고 싶은데 PASCAL VOC이나 ILRVSC같이 용량이 큰 데이터로 하면 너무 시간이 오래걸리니까 좀 그렇다하면 위 사이트에서 이용하는 것도 좋을 것 같다.
이 데이터 셋에 대해서 간단히 설명하자면, 전체 이미지는 364개다. 구체적으로 train, validation, test 셋은 아래와 같이 구성된다. 굉장히 적어보이쥬?

클래스의 분포는 아래와 같다. RBC가 적혈구 WBC가 백혈구, 그리고 Platelets는 혈소판이다. 보면 굉장한 클래스 간 불균형이 있음을 알 수 있다. 불균형은 안 좋다! 왜냐하면 RBC에 대한 데이터가 많기 때문에 감지하는 모든 boudning box를 여차하면 다 적혈구로 탐지해버릴 수도 있기 때문이다. 뭐 그건 그렇다.

데이터 셋을 다운 받으면 이미지가 담긴 jpg 파일과 bounding box 그리고 label의 정보가 담긴 xml 파일이 있다. 1.jpg, 1.xml, 2.jpg, 2.xml이런식으로 쭉 있다.
일단 이미지를 먼저 보자. jpg를 하나 가져와 보면 이렇게 생겼다.

실은 난 의학쪽은 모른다. 이쪽으로는 전혀 무지함. 그래서 위 사진을 봐도 아무것도 모른다. 대신 딥러닝은 조금 하지!
그다음은 xml파일이다. PASCAL VOC 데이터 셋의 경우, annotation 파일은 xml 형식이다. COCO나 YOLO는 json파일을 이용하는 것 같다. xml에 대해서는 그냥 .txt 같은 확장자 정도로만 알아두면 될 것 같다. 구체적으로 PASCAL VOC 데이터 셋의 annotation 파일에 대해서 알고 싶다면 아래의 링크를 참고하자. https://deepbaksuvision.github.io/Modu_ObjectDetection/posts/02_01_PASCAL_VOC.html
열어보면 아래와 같이 생겼다.
<annotation>
<folder></folder>
<filename>BloodImage_00001_jpg.rf.d702f2b1212a2ed897b5607804109acf.jpg</filename>
<path>BloodImage_00001_jpg.rf.d702f2b1212a2ed897b5607804109acf.jpg</path>
<source>
<database>roboflow.ai</database>
</source>
<size>
<width>640</width>
<height>480</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>WBC</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<occluded>0</occluded>
<bndbox>
<xmin>69</xmin>
<xmax>287</xmax>
<ymin>316</ymin>
<ymax>481</ymax>
</bndbox>
</object>
<object>
<name>RBC</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<occluded>0</occluded>
<bndbox>
<xmin>347</xmin>
<xmax>447</xmax>
<ymin>362</ymin>
<ymax>455</ymax>
</bndbox>
</object>
<object>
<name>RBC</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<occluded>0</occluded>
<bndbox>
<xmin>54</xmin>
<xmax>147</xmax>
<ymin>180</ymin>
<ymax>300</ymax>
</bndbox>
</object>
(...)
</annotation>
보면 object 태그가 여럿 있는 것을 알 수 있다. object 태그가 하나의 객체에 대한 정보를 담고 있다.
객체의 정보(xml)를 이미지 파일(jpg)에 아래와 같은 코드를 이용해서, 아래와 같이 띄울 수 있다.
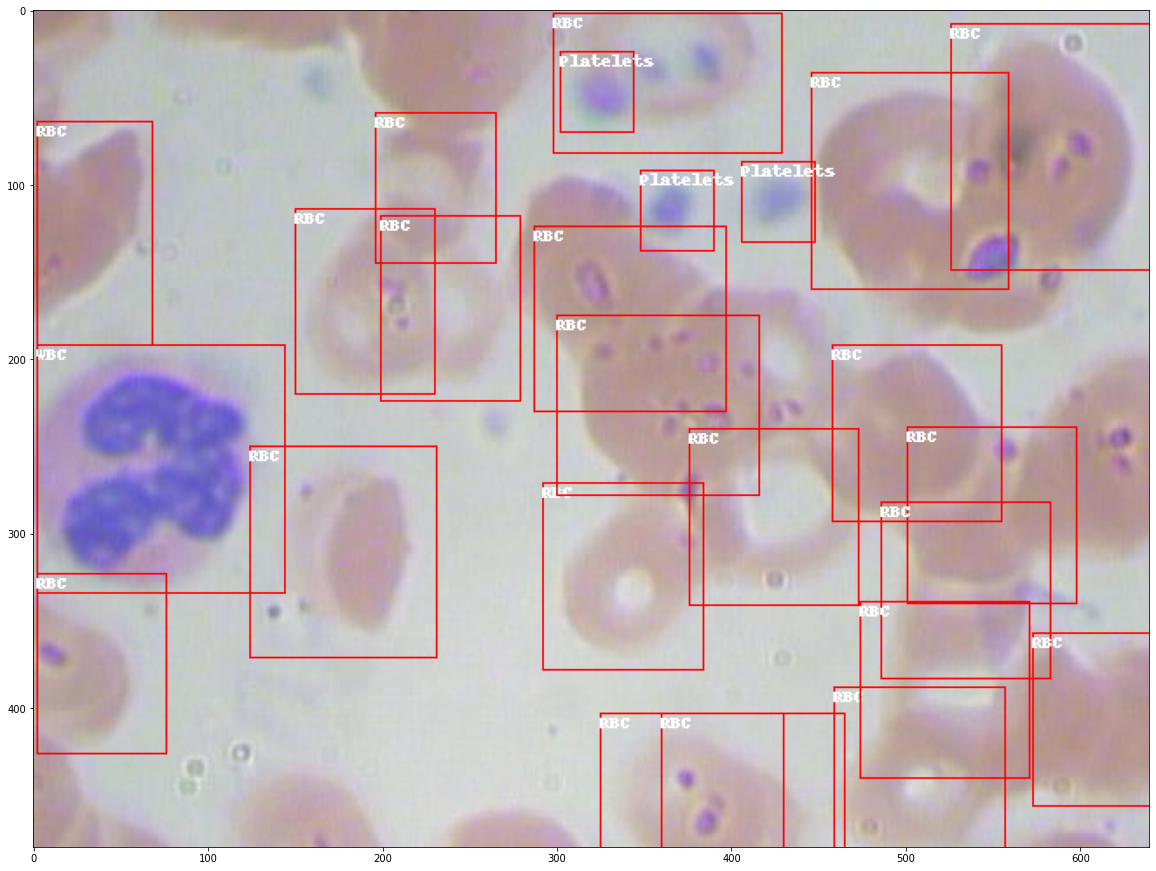
## 원본 이미지를 bounding box, class와 함께 읽어오기
import matplotlib.pyplot as plt
from PIL import Image
from PIL import ImageFont
from PIL import ImageDraw
temp = Image.open('/content/BCCD/train/images/BloodImage_00030_jpg.rf.71385416b4e288babd3e52de3941fc6b.jpg').convert("RGB")
draw = ImageDraw.Draw(temp)
xml = open("/content/BCCD/train/annos/BloodImage_00030_jpg.rf.71385416b4e288babd3e52de3941fc6b.xml")
tree = ET.parse(xml)
root = tree.getroot()
size = root.find("size")
width = size.find("width").text
height = size.find("height").text
depth = size.find("depth").text
objects = root.findall("object")
# object가 여러개 있으므로 순회하면서 다 정보를 받아들인다
for object_ in objects:
class_ = object_.find("name").text
bndbox = object_.find("bndbox")
xmin = int(bndbox.find("xmin").text)
xmax = int(bndbox.find("xmax").text)
ymin = int(bndbox.find("ymin").text)
ymax = int(bndbox.find("ymax").text)
# 사각형을 그리고, class를 그림 위에 쓴다
draw.rectangle(((xmin,ymin),(xmax,ymax)),outline='red')
draw.text((xmin,ymin),class_)
plt.figure(figsize=(20,20))
plt.imshow(temp)
plt.show()
XML 파일을 파싱하면서 느낀 건 왠지 크롤링이랑 비슷하다는 점이다. 보면 findall 이나 .text 같은 걸 쓰는데 이게 굉장히 BeautifulSoup의 findAll 이나 .get_text()를 닮지 않았는가? 하여간에 배운 게 어디든 써먹을 데가 있다니까! 이래서 공부를 못 끊어..
하여간 위 사진을 보면 알 수 있듯이, 하나의 이미지에서도 굉장히 많은 객체가 있다. 씁 PASCAL VOC도 이렇게 많지는 않았던 것 같은데.
그렇담 얼추 데이터 소개가 끝났다!
이후로는 R-CNN의 step 별로 구현한 파이썬 파일을 올린다. 수제라서 맞는지 아닌지 잘 몰라요. 열심히 공부중이에오.
그래서 이렇게 데이터 셋을 다운 받는 cmd 파일도 만들었다.
get_data.cmd
## pip install wget
mkdir content
cd content
mkdir BCCD
python -m wget https://public.roboflow.com/ds/L7rUTKGfz8?key=xXzeVq2N18 -o ./BCCD/data.zip
unzip ./BCCD/data.zip
move ./test ./BCCD
move ./train ./BCCD
move ./valid ./BCCD
mkdir .\BCCD\train\images
mkdir .\BCCD\train\annos
mkdir .\BCCD\test\images
mkdir .\BCCD\test\annos
mkdir .\BCCD\valid\images
mkdir .\BCCD\valid\annos
cd ..
python get_data.pyget_data.py
train, test, valid 셋 안에 jpg랑 xml이 같이 있는게 불편해서 그냥 따로 파일을 분리해서 만들었다. get_data.py가 이 역할을 한다.
import os
for file in os.listdir('content/BCCD/train'):
if file == 'annos' or file == 'images': continue
if file.split(sep='.')[3] == 'jpg':
os.rename("content/BCCD/train/"+file, "content/BCCD/train/images/"+file)
else: os.rename("content/BCCD/train/"+file, "content/BCCD/train/annos/"+file)
for file in os.listdir('content/BCCD/valid'):
if file == 'annos' or file == 'images': continue
if file.split(sep='.')[3] == 'jpg':
os.rename("content/BCCD/valid/" + file, "content/BCCD/valid/images/" + file)
else:
os.rename("content/BCCD/valid/" + file, "content/BCCD/valid/annos/" + file)
for file in os.listdir('content/BCCD/test'):
if file == 'annos' or file == 'images': continue
if file.split(sep='.')[3] == 'jpg':
os.rename("content/BCCD/test/" + file, "content/BCCD/test/images/" + file)
else:
os.rename("content/BCCD/test/" + file, "content/BCCD/test/annos/" + file)
다음 포스팅에선 selective search를 통해 2000개의 region proposal을 생성하고, 그 사이즈를 동일하게 맞추는 부분을 게시하도록 하겠다. 이렇게 하나하나씩 올려야 성취감이 빨리 느껴져서 그렇다...
'딥러닝 > 프로젝트' 카테고리의 다른 글
| [Kaggle] CT Medical Image - (0) 서론, 액션 플랜 (0) | 2021.09.25 |
|---|---|
| [개인]R-CNN 을 이용한 BCCD type 분류 -(3)linear svm, (4)결론 (0) | 2021.06.29 |
| [개인]R-CNN 을 이용한 BCCD type 구분 -(2) fine tuning (0) | 2021.06.29 |
| [개인]R-CNN 을 이용한 BCCD type 구분 -(1) selective search (0) | 2021.06.23 |
| [개인]합성곱 신경망을 통한 이미지 분류 (0) | 2021.04.26 |



댓글