Going deeper convolutions
AlexNet이 나오고 벌써 2년이 지난 2015년이다. 중학교 때 도덕 공부하지 말고 인공지능이나 공부했으면 난 벌써 척척박사였을지도 모르겠군. 참고로 말하자면 Fast R-CNN이 나왔던 시점도 2015년이다. 왜 R-CNN에서 AlexNet을 쓰나 했더만.. classification이랑 detection이 이렇게 구분되어서 발전해왔을 줄은 몰랐다. (약간 그 미분과 적분은 별개의 학문이었는데 나중에 그 연결점을 찾아서 미적분이 된 것처럼.. 아닌가? ㅎㅎ)
참고로 내가 느낀건데 약간 제대로 이해를 못하면 영어를 많이 쓰는 것 같다. (약간 region proposal 같은 그런 용어 말고 construct나,,) 내가 아는 동산데 뭔가 내용을 이해 못하니까 뭐라고 해석하는 게 적절할지 몰라서 영어로 써버리는 것 같았다. 그래서 최대한 한글로 쓰려고 노력하고 있다.
1. introduction
CNN이 제안되었을 때, 컴퓨팅 자원의 한계로 인해서 실질적으로 사용하지 못하다보니 그다지 관심을 받지 못했다. 하지만 AlexNet으로 인해서 성공적으로 딥러닝이 practical하게 사용할 수 있게 되었고, CNN 을 활용한 이미지 인식, 객체 검출(image recognition, object detection)연구들이 활발해졌다. 이는 단순히 하드웨어의 성능이나 큰 데이터셋의 결과가 아니라, 새로운 아이디어, 알고리즘 그리고 모델 구조 덕분이라고 저자는 강조하고 있다. 본 논문을 통해서 소개할 GoogLeNet은 AlexNet에 비해 12배 가량 적은 파라미터를 이용하면서도 그에 비해 정확한 결과를 얻을 수 있었다.
GoogLeNet은 정확하게 숫자를 고정하기보다는 보다 유연한 구조를 취한다. 또한 학문적 연구는 지양하고 real world 에서 이용될 수 있도록 연구하기 위해, 연산을 1.5biliion 으로 제한했다.
본 논문에서는 효과적인 컴퓨터 비전 DNN architecture를 살펴보며 이를 "Inception"으로 부르기로 한다. 인셉션의 "we need to go deeper"라는 밈에서 퍼왔다고 한다. 이런 논문 처음이야.. 이때 본 논문에서 deep은 크게 두 가지 의미를 가진다: (1) a new level of organization in the form of the "Inception module" (2) increased network depth 즉, 새로운 인셉션 모듈이라는 모듈을 도입했다는 점에서, 그리고 말 그대로 깊은 네트워크 구조를 구현했다는 점에서 deep 하다는 단어를 사용했다고 한다. 한편 이 GoogLeNet(이하 googlNet) 은 ILSVRC 2014 (classification, detection)데이터 셋을 통해 그 성능을 증명했다.

2. Related Work
CNN은 전형적으로 따르는 구조가 있다. 여러번 합성곱 망을 거친 이후에 여러 개(또는 하나)의 FC 층을 거침으로써 task를 수행하는 구조이다. 이 당시 연구는 더 큰 데이터 셋에서도 잘 classification하도록 층의 수를 늘리거나, 층의 사이즈를 늘리는 동시에 드롭아웃을 통해 과적합을 방지하는 방향으로 흘러가고 있었다.
비록 max-pooling 층을 거치면 정확한 공간적 정보를 잃는다는 concern이 있기는 하지만, 실제로 max pooling 층을 사용해서 좋은 성과를 낸 연구들이 많다(여기에 내가 읽었던 R-CNN도 들어간다 반갑다 야!). 그 중에서도, 저자가 주목한 건 다양한 스케일을 처리하기 위해서 여러 가지 사이즈의 필터를 사용한 모델이다. 한편 이때 사용한 필터는 Gabor filter로서 파라미터를 통해서 필터 내의 가중치를 수정할 수는 있지만, 역전파를 통해서 학습하는 과정은 없다. Inception 모델에서는 이와 유사한 모델을 사용하기는 했지만, 필터(내의 가중치)는 학습된다는 점에서 다르다. 더욱이 Inception 층은 여러 번 반복되고, 특히 googleNet의 경우 22개의 인셉션 층이 있다.
한편 본 논문에서 참고한 Network-in-Network 모델에 대해서 간략하게 설명하자면

전체적인 구조는 아래처럼 생겼다. 단 매핑된 곳에서 합성곱 계산을 하는 것이 아니라 바로 FC layer 즉 MLP를 연결하고, 이를 통해서 계산 된 값을 다음 layer에 넣는 구조이다. 이를 합성곱의 관점에서 생각해보면, additional 1x1 convolution 층이라고 볼 수 있다. (그리고 그 뒤에 rectified linear activation, ReLU를 적용시킨다) 본 googleNet에서는 위 NIN에서 제안한 것처럼 1x1 convolution을 거친 후에 필터 계산을 한다.

이때 1x1 합성곱을 사용함으로써 차원 축소가 가능해지고, 이가 computational bottleneck를 해소한다.(한국어로 뭐라고 해야할지 모르겠다) 이를 통해 크게 두 가지 장점이 있다: (1) increasing detpth 즉 깊이를 늘리는 것이 가능해지고 (2) and also width 너비를 늘리는 것이 가능해진다.
(*width: the numbers of units, 각 레이어의 유닛/노드 수)
이후에는 R-CNN 이야기가 나온다. R-CNN은 객체 탐지 알고리즘으로 이를 크게 두 가지 과정(pipeline)으로 구분할 수 있다. low level cues를 활용해서 후보 영역들을 뽑는 과정1, 그리고 그 영역을 classification 하는 과정2. googleNet을 object detection 영역에 활용해보기 위해서 R-CNN의 이러한 과정을 따라 시험해봤다고 한다. 하지만 몇 가지 사항을 수정했다. R-CNN의 경우 selective search를 통해서 region proposals를 추출했으나, googlNet 팀은 multi box prediction을 이용하고, 여러 모델을 앙상블 하는 등의 modification을 통해 보다 좋은 성과를 얻고자 했다.
3. Motivation and High Level Considerations
가장 직관적으로 DNN의 성능을 개선하는 방법은 depth와 width의 사이즈를 키우는 것이다. 하지만 크게 두 가지 문제점이 존재한다.
- more prone to overfitting
더 큰 사이즈라는 말은 곧 파라미터의 수가 많음을 의미하는데, 이는 과적합으로 이어지기 쉽다. 과적합을 해결하는 방법 중 가장 쉬운 방법은 데이터 수를 늘리는 일이다. 하지만 이게 cv 쪽에서는 쉽지 않다. 결국 인간을 통해서 데이터를 만들어야 하기 때문이다!

위와 같은 그림 두 장을 보자. (a)와 (b) 는 서로 종류가 다른 개다. 컴퓨터가 이를 학습하기 위해선 정답 label이 있어야 하는데, 그럼 그 정답을 누가 달아주는가 하면,, 바로 인간이다! 하지만 아무 인간이나 되는 건 또 아니다. 위 사진에서 뭐가 시베리안 허스키고 에스키모인지 구분할 줄 아는 사람이어야 한다. 따라서 정확하게 label된 질 좋은 데이터 셋을 얻는 건 상당히 어렵다. 따라서 이미지 수를 늘림으로써 과적합을 해결할 수 없기 때문에, 다른 대안이 있어야만 한다.
사족
후... 질 좋은 이미지 셋 찾기 어렵다는 말에 난 너무 공감한다ㅠㅠ 내가 인턴 일을 하면서 segmentation할 일이 생겼는데 제대로 된 학습 데이터가 없지 뭔가! 내가 원하는 카테고리에 해당하는 이미지가 없으면 내가 만들어야 하는데 labelme 라는 툴을 썼다. 아니 근데 이게 진짜 생노가다다. 그래서 인턴 하면서 정말 많은 회의감이 몰려왔다. 그런데 결국 그렇게 노가다 한 data 를 안 쓰는 게 더 어이없음 아니다 이제는 어이없어 할 힘도 안 난다 정말 이때 인턴 일을 때려치고 싶었다. 하지만 그래도 시원한 곳에서 몰래몰래 공부하는 재미가...
- increased use of computational resources
Another drawback of uniformly increased network size is the dramatically increased use of computational resources.
=> 위 두 가지 문제점은 결국 fully connected를 sparsely connected architecture로 바꿈으로써 해결할 수 있다.
하지만 인프라는 dense한 연산에 최적화되어 있었기 때문에 sparsity를 도입하면 계산이 빨라져야 함에도 불구하고, 그러한 효과를 볼 수 없었다.
자세한 내용
만약 데이터 셋의 분포가 크고, spare(희소)한 dnn 구조를 가진다면, 최적의 네트워크 토폴로지를 앞선 레이어의 활성화된 값의 correlation값을 분석하고, highly correlated된 outputs로 뉴런들을 클러스팅함으로써 층별로 construct할 수 있다.
두번째 문장은 해석보다는 영어로 보는 게 자연스러울 것 같다. 바꿔 쓴다.
If the propability distribution of the data-set is representable by a large, very sparse deep neural network. then the optimal network topology can be constructed layer by layer by analyzing the correlation statistics of the activations of the last layer and clustering neurons with highly correlated outputs.
갈수록 영어가 익숙해진다. 한국어로는 뭐라고 해야 해..??
그러나 앞서서 sparse connected 한 구조를 사용한다고 했는데, 오늘날 연산 시설?(infrastructure)은 non-uniform 한 sparse 데이터 구조에서는 매우 비효울적이다. 심지어 sparse를 이용해서 100배 정도 연산이 줄어도, 여전히 overhead of lookups 와 cache misses 로 인해서 그다지 성능이 좋지 않다. 즉 CPU나 GPU 는 uniform한 dense matrix multiplication에 최적화?되어 있기 때문에 이들을 이용해도 여전히 성능이 안 좋다는 뜻이다. 더욱이 정교한 가공이 필요하기 때문에 더욱 어렵다. 대부분은 sparsity를 convolution을 통해서만 이용한다고 한다.
왜 sparsity가 convolution을 통해서 이용되는가?
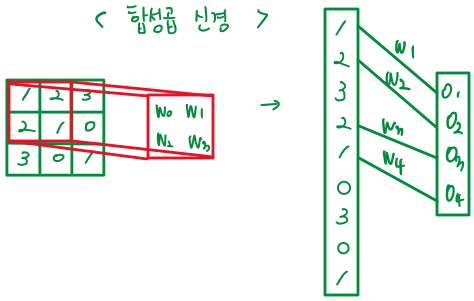
왼쪽은 다층 퍼셉트론, 오른쪽은 합성곱 신경망이다.
보면 알 수 있듯이 왼쪽은 모든 node가 빡빡하게 서로 연결되어 있다. dense~
하지만 오른쪽을 보면 지금 네 개만 연결되어 있다. 연결되지 않은 부분은 모두 가중치가 0인 셈이다. 그래서 sparse~
그렇다면 sparsity를 이용하는 것을 포기해야 하는가? GoogleNet 팀은 상대적으로 dense한 submatrices로 바꿔서 sparsity를 취하지만 계산은 dense하게 수행할 수 있도록 architecture를 구성했다.
4. Architectural Details
따라서 인셉션 구조는 최적의 loca sparse structure를 구성해서, dense computation을 수행할 것인가, 라는 고민에서 출발됐다. 디테일은 아래와 같다.
patch alignment(필터의 사이즈가 짝수일 때, 2*2같은 거, 매핑이 난해할 때가 있다. 이를 patch alignment라고 한다) 를 피하기 위해서 1*1, 3*3, 5*5 사이즈의 필터를 이용했다. 그러나 이는 필요에 의해서 그랬다기 보다는 편의 convenience를 위해서였다. 동시에 pooling layer도 병렬적으로 계산한다. 따라서 인셉션 모델의 naiive한 폼은 아래와 같이 생겼다.

1*1, 3*3, 5*5 필터를 거친 특성맵 역시도 사이즈가 28*28인 이유는, padding을 통해 원본 사이즈를 유지하기 때문이다. (keras에서 padding="same"이라는 게 있더라)
하지만 이렇게 되면 어떤 문제가 생기는가? 파라미터 수가 매우매우매우 많아진다. 이는 결국 output의 수가 기하급수적으로 증가하는 것을 막을 수 없을 것이다. 그래서 naive한 form이다. 따라서 이를 해결하기 위해 dimension reduction은 필수적이었으며, 1*1 합성곱을 상대적으로 필터의 크기가 큰 3*3와 5*5를 수행하기 전에 시행했다. 따라서 dimension reduction을 한 form은 아래와 같다.

1*1 합성곱을 하게 된다면, 특성맵의 사이즈는 바꾸지 않지만(28*28) 특성맵의 필터 수는 1*1 합성곱 필터의 수를 따르기 때문에 이를 조절하여 차원을 줄일 수 있게 되는 것이다. 또한 이때 1*1 합성곱을 하고 나서 rectified linear activation(ReLU)를 시행해줌으로써 이 1*1합성곱은 dimesnion reduction 뿐만 아니라 비선형성을 추가한다는 두 가지의 이점을 가지게 된다.
위 인셉션 모듈을 쌓아올리면서 가끔씩 stride가 2인 maxpooling을 시행한다. resolution(아마도 화소 밀도)를 절반으로 줄여주기 위함이다.
기술적인 이유(memory efficiency during training)로 위 인셉션 모델은 좀 더 나중 layer에서 시행하고, 앞에서는 전통적인 CNN의 구조를 따른다.

위 사진은 googleNet의 전체 architecture인데 여기서 노란색으로 하이라이트 친 부분에서 conv, pool, LRN을 시행한 전통적인 CNN의 구조를 따르고 있는 것을 확인할 수 있다. 이후로는 위에서 보았던 dimension reduction을 한 인셉션 모듈이 반복돼서 쌓이고 있다. 하지만 이는 반드시 필요한 것은 아니라고 한다.
이 구조가 가지는 장점으로는 무엇보다도 각 스테이지에서 기하급수적으로 계산 복잡성을 증가시키지 않고도, 각 레이어의 필터 수를 증가시킬 수 있다는 것이다. 또한 다른 이점으로는, 서로 다른 스케일의 필터를 병렬적으로 수행함으로써 다양한 사이즈의 피쳐를 추출하는 우리의 시각적 정보에 대한 직관과 일치한다는 점이다.
5. GoogLeNet
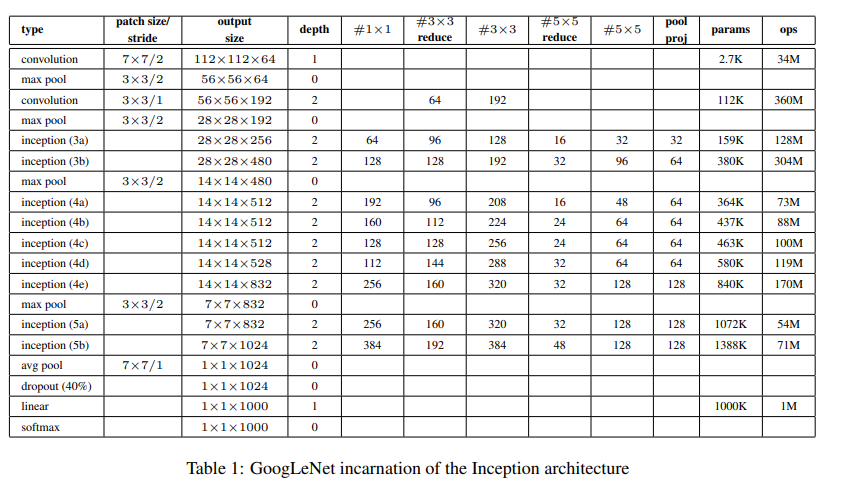
여태까지 살펴본 googleNet에서 사용한 자세한 디테일은 위와 같다.
위에 보면 #3 X 3 reduce라는 게 있는데, 이는 1*1 convolution을 거친 후 3*3 convolution을 거치기 전의 필터수이다.
위의 표에서 보면 avg pooling layer 다음에 AlexNet에서 봤던 것 같은 FC layer는 없는 대신, linear layer가 있다. FC layer를 제거하고 나서 오히려 에러율이 줄어들었다는 사실을 발견했기 때문이다. 그럼에도 불구하고 완전히 없애지 않고, 여전히 linear layer 하나를 남긴 것은 fine-tuning에 용이하기 때문이다. 그러나 FC layer를 없애는 것은 오히려 에러율 감소에 긍정적인 영향을 주었지만 dropu out layer는 여전히 필요했다고 한다.
깊은 네트워크 때문에, 효과적으로 역전파를 통해 가중치를 업데이트 하는게 중요한 문제 중 하나였다. 이를 해결하기 위해서 보조의 분류 레이어auxiliary classifier를 네트워크 중간에 두었다.

하이라이트로 표시한 softmax0, softmax1가 그 부분이다. 모델이 학습할 때 보조 분류기를 통해서 계산된 loss의 0.3만큼 더해진다. (weighted by 0.3) 한편 테스트할 때는 이러한 네트워크는 discard했다고 한다.
이에 대한 자세한 디테일이다.
- An average pooling layer with 5×5 filter size and stride 3, resulting in an 4×4×512 output for the (4a), and 4×4×528 for the (4d) stage.
- A 1×1 convolution with 128 filters for dimension reduction and rectified linear activation.
- A fully connected layer with 1024 units and rectified linear activation.
- A dropout layer with 70% ratio of dropped outputs.
- A linear layer with softmax loss as the classifier (predicting the same 1000 classes as the main classifier, but removed at inference time).
6. Training Methodology
CPU에 기반한 학습만 진행했다고 한다.
- asynchronous stochastic gradient descent with 0.9 momentum
- fixed learning rate schedule(epoch 8회당 lr을 4%씩 줄임)
- Polyak averaging (at inference time)
한편 image sampling에 굉장히 다양한 방법을 시도해서 정확하게 무엇이 결과 개선에 영향을 주었는지 모른다고 한다.
이미지 내에서 8%~ 100% 정도의 크기를 차지하는 객체를 포함시켰고(즉 다양한 사이즈의 객체), 또 가로와 세로비를 3:4와 4:3 중에서 랜덤하게 골랐다고 한다.
랜덤한 보간법(bilinear, area, nearset neighbor and cubic)을 resize하는데 이용했다고 한다.
하지만 이 중 어떤게 좋은 영향을 줬는지 딱 잘라서 말하기는 애매하다고 한다.
7. ILSVRC 2014 Classification Challenge Setup and Results
googleNet의 서로 다른 7개의 버전을 독립적으로 훈련시킨 후에 예측할 때는 앙상블했다고 한다. sampling 방법과 image가 input되는 랜덤한 순서를 제외하고는 모든 설정이 같았다고 한다.
AlexNet에 비해 aggressive cropping을 시행했다고 한다. 우선 이미지를 짧은 변 가준으로 4가지 스케일로 resize한다(256, 288,320,352). 그 후엔 왼쪽, 센터, 그리고 오른쪽 square를 take 한다. 각 square에서 4가지 corner와 가운데에서 224*224 crop을 한다. 그리고 각각을 좌우 반전 시킨다. 이를 통해서 한 이미지 당 4*3*6*2 = 144 개의 크롭을 얻는다. 하지만 이렇게까지 많은 crop이 실적용에는 필요하지 않을 것으로 예상된다고 한다. 어느 적정 수준만 넘어가면 괜찮은 걸로!
위의 과정을 거쳐 나온 크롭 별 softmax 확률을 평균 낸 후 최종 예측을 얻는다.

8. ILSVRC 2014 Detection Challenge Setup and Reulsts
이 GoogleNet을 단순히 Classification에만 해볼 것이 아니라, object Detection에도 수행해보고 싶었던 GoogleNet 팀..
R-CNN과 유사한 구조를 가진다. 대신 selective search와 multi box prediction을 함께 사용함으로써 resion proposal step을 개선시켰다고 한다. FP의 수를 줄이기 위해서 superpixel 사이즈르 2배 늘였다. 또한 200개의 background 이미지를 사용함으로써 R-CNN에서 사용했던 proposal의 60%정도만 사용했음에도 불구하고, 정확성을 약 1%정도 높였다. 한편 bounding box prediction을 refine하는 bounding box regression은 시간부족으로 시행해보지 못했다고 한다.
결과는 다음과 같다.

9. Conclusions
결국 sparse한 construct를 dense한 block을 이용함으로써 좋은 성과를 낼 수 있었다.
[reference]
https://arxiv.org/pdf/1409.4842.pdf
https://89douner.tistory.com/62?category=873854
https://poddeeplearning.readthedocs.io/ko/latest/CNN/GoogLeNet/
https://bi.snu.ac.kr/Courses/ML2016/LectureNote/LectureNote_ch4.pdf
'딥러닝 > CV 논문' 카테고리의 다른 글
| [Classification] ViT: Vision Transformer (0) | 2021.07.29 |
|---|---|
| [NLP] Tansformer (0) | 2021.07.28 |
| [Object Detection] Fast R-CNN (0) | 2021.07.07 |
| [Object Detection] R-CNN (3) | 2021.06.05 |
| [Classification] Alexnet (1) | 2021.05.06 |




댓글