[참고자료]
https://www.youtube.com/watch?v=MghbHLuupoA
https://ratsgo.github.io/speechbook/docs/neuralam/ctc
https://lynnshin.tistory.com/42
논문 4개는 너무 벅차서.. 본 포스팅은 영상과 리뷰 포스팅 위주로 흘러갑니다
[음성 데이터 활용 분야]
음성 데이터 분석은 어떤 분야에 활용할 수 있는가?
음성인식STT/ASR, 음성합성TTS, 음성비서, 스마트 스피커 등
[음성 데이터의 구조]
- Waveform(음성 파일)
음성 데이터는 보통 waveform으로 저장된다. 소리를 어떤 주기로 쪼개서 그 세기를 기록한 것
하지만 이 waveform을 분석하지는 않고, 푸리에 변환을 거쳐서 spectrogram 이라는 형태로 변형해서 분석에 이용한다. 스펙토그램은 아래와 같이 생겼다. waveform을 스펙토그램으로 변환하는 과정은 음성 데이터 분석에서 feature extraction 인 셈이다. 이 스펙토그램에서 우리가 찾고자 하는 text를 분석한다.
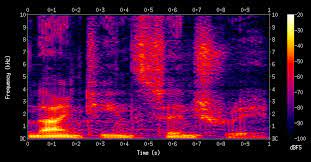
밑에가 낮은 주파수 위에가 높은 주파수
- Utterance(발화 텍스트)
- Alignment(위치 정렬): 몇 초부터 몇 초가 어떤 단어에 해당하는가? (보통 딥러닝으로 때려맞춤)
[기존의 학습 방식]
waveform에서 feature를 뽑고 rule based decoder를 통해 text를 예측함.
이때 rule based decoder라고 부르는 이유는 별개의 acoustic model과 language model을 일일이 dictionary(lexion)을 이용해서 하나씩 맞추었기 때문!
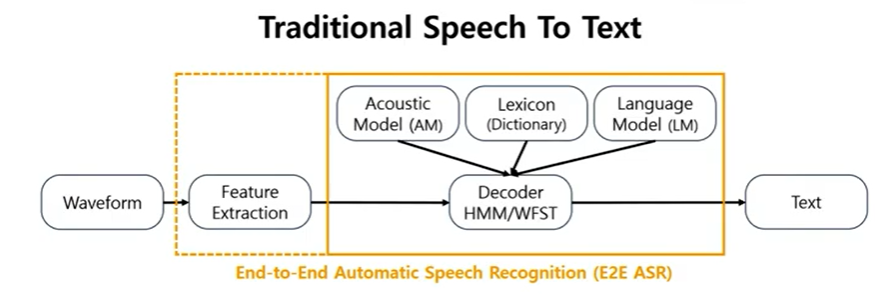
그러나 딥러닝으로 음성 데이터를 분석한다고 해도 여전히 feature extraction과 같이 전처리와 후처리가 굉장히 중요함
또한 alignment 의 문제점!
음성 데이터의 어떤 부분이 텍스트의 어떤 부분과 대응하는가?
=> 경계가 명확하지 않음, 프레임을 나누기 어려움
아래처럼 1000개의 feature 가 있음에도 불구하고 label은 12개뿐, alignment가 어려움

[acoustic model]
Deep Speech 라는 논문에서 소개한 모델 중 acoustic model 일부만 가져와봤다!
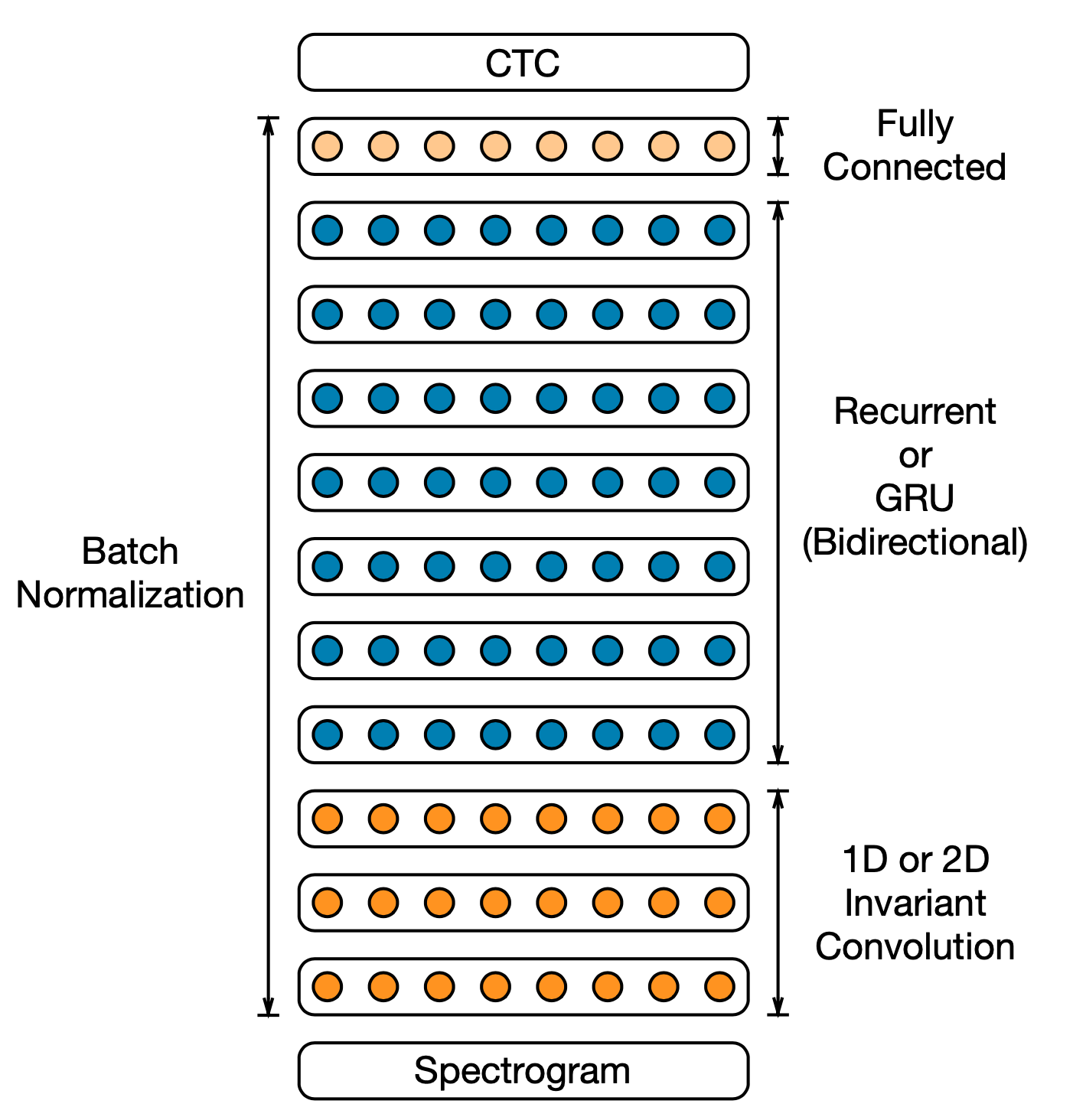
스펙토그램이 들어오면 그걸 CNN 과 RNN 그리고 FC layer를 거쳐서 최종적인 CTC를 산출한다.
이 그림에서 보면 전부 8개로 동일한 feature가 유지되는 것처럼 보이지만, 사실은 stride 2를 통해서 feature 수를 줄이고 있다.
처음에 1000개가 들어왔다면 반씩 줄어서 500, 250, 125. 즉 125개의 feature가 양방향 RNN 의 input으로 들어간다.
[CTC]
이후에 나오는 CTC는 길이를 맞추는 알고리즘으로 딥러닝과는 무관하다고 한다.
핵심 아이디어는 음성 길이에 맞게 텍스트의 길이를 확장하는 것!!
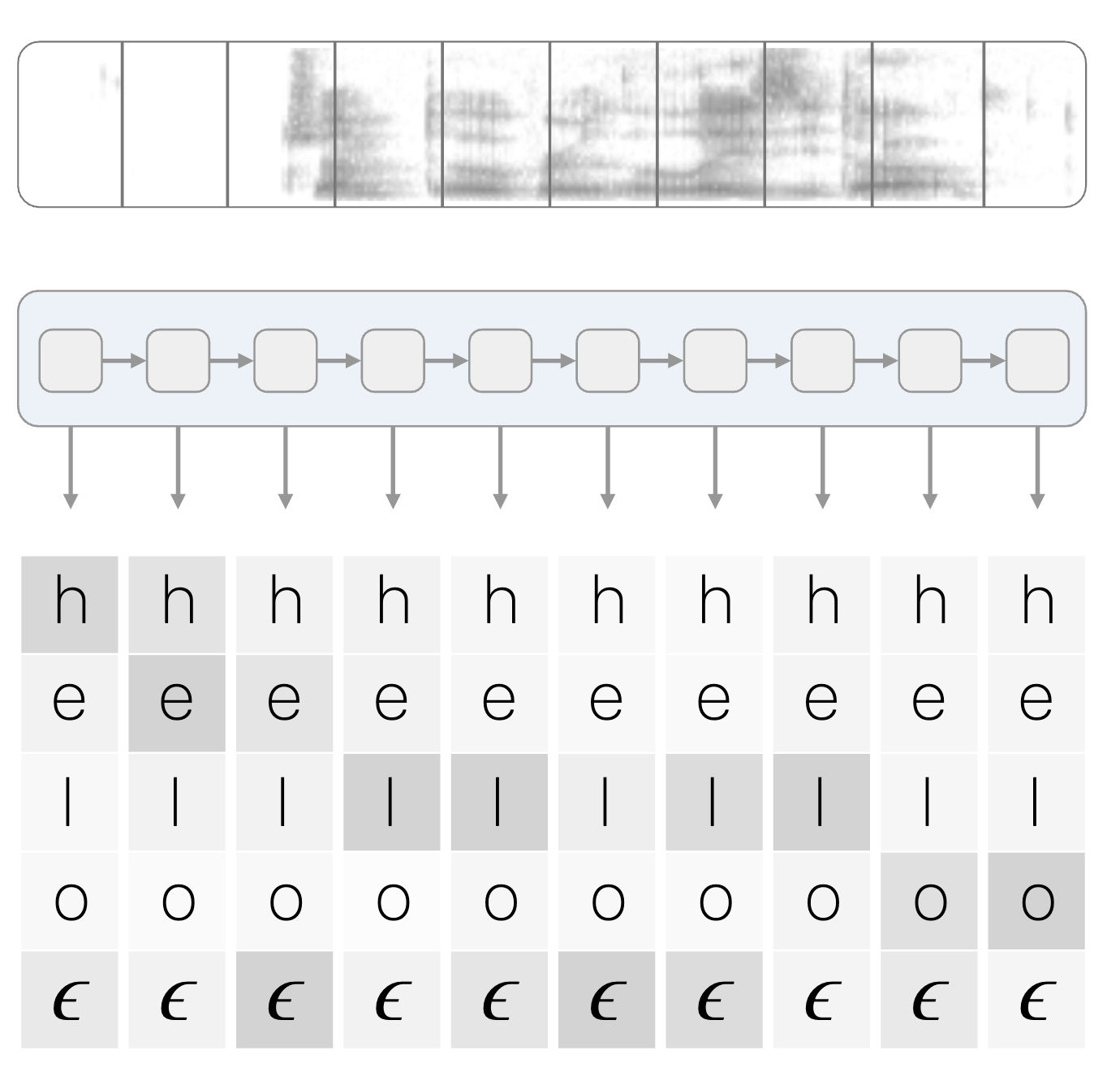
CTC의 입력값은 다음과 같다.
위 그림에서는 입력값이 RNN을 통해서 계산된다.
저기서 가장 아래 문자는 blank를 뜻한다.
CTC 레이어가 입력 받는 확률 벡터의 차원수는 레이블 수 + 1입니다. 1이 추가된 이유는 ε, 즉 blank가 포함되어 있기 때문입니다. 예컨대 한국어 전체 음소 수가 42개라면 CTC에 들어가는 확률 벡터의 차원 수는 43차원이 됩니다.
그럼 이거 가지고 어떻게 하느냐?
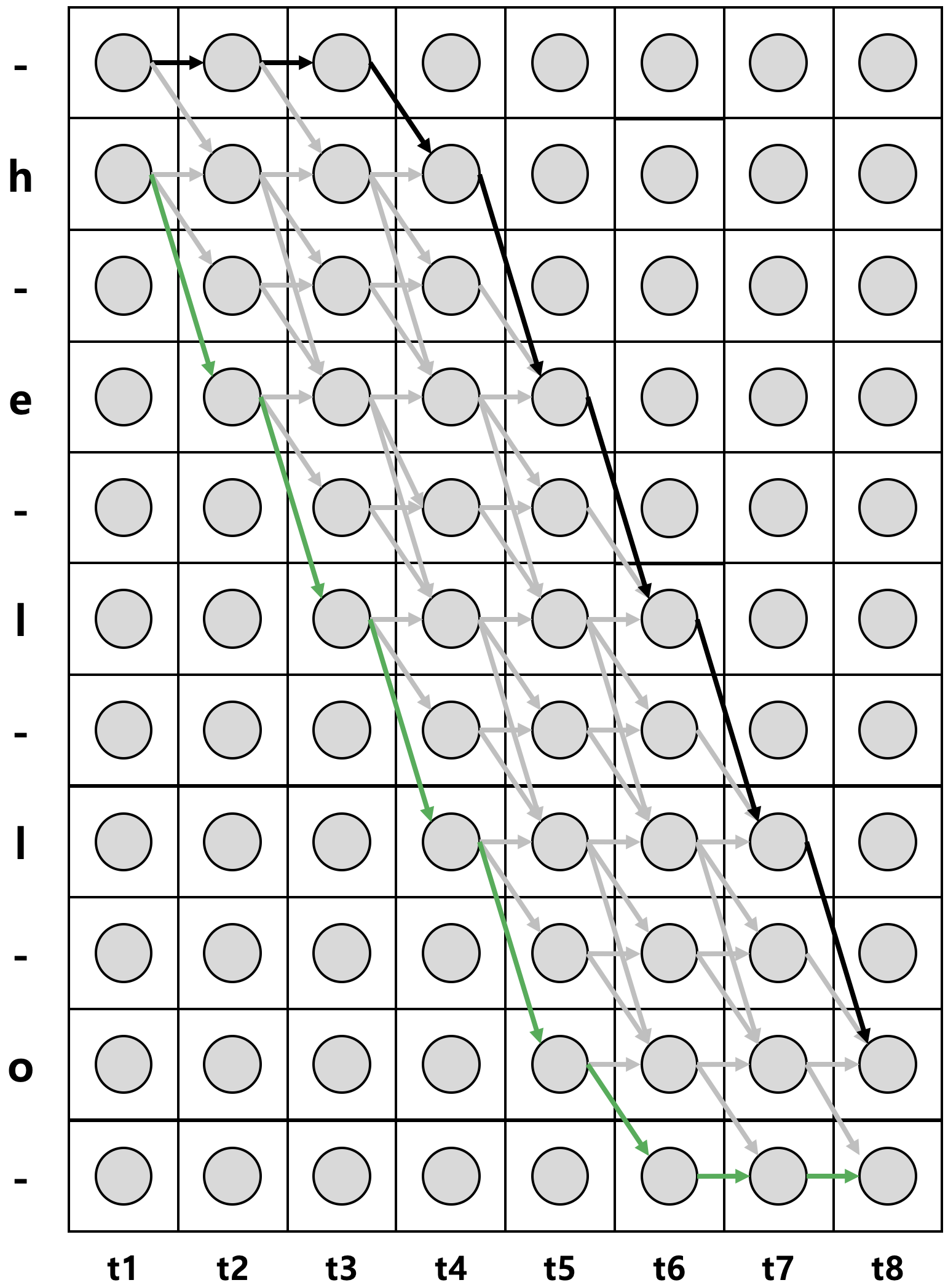
아래와 같이 예측되는 음소와 blank 를 모두 나열한다.
가능한 경로들을 모두 탐색해서 확률값을 계산한다.
따라서
특정 음성 데이터가 주어졌을때, 계산되는 확률값을 최대화하는 방식으로 이루어진다.
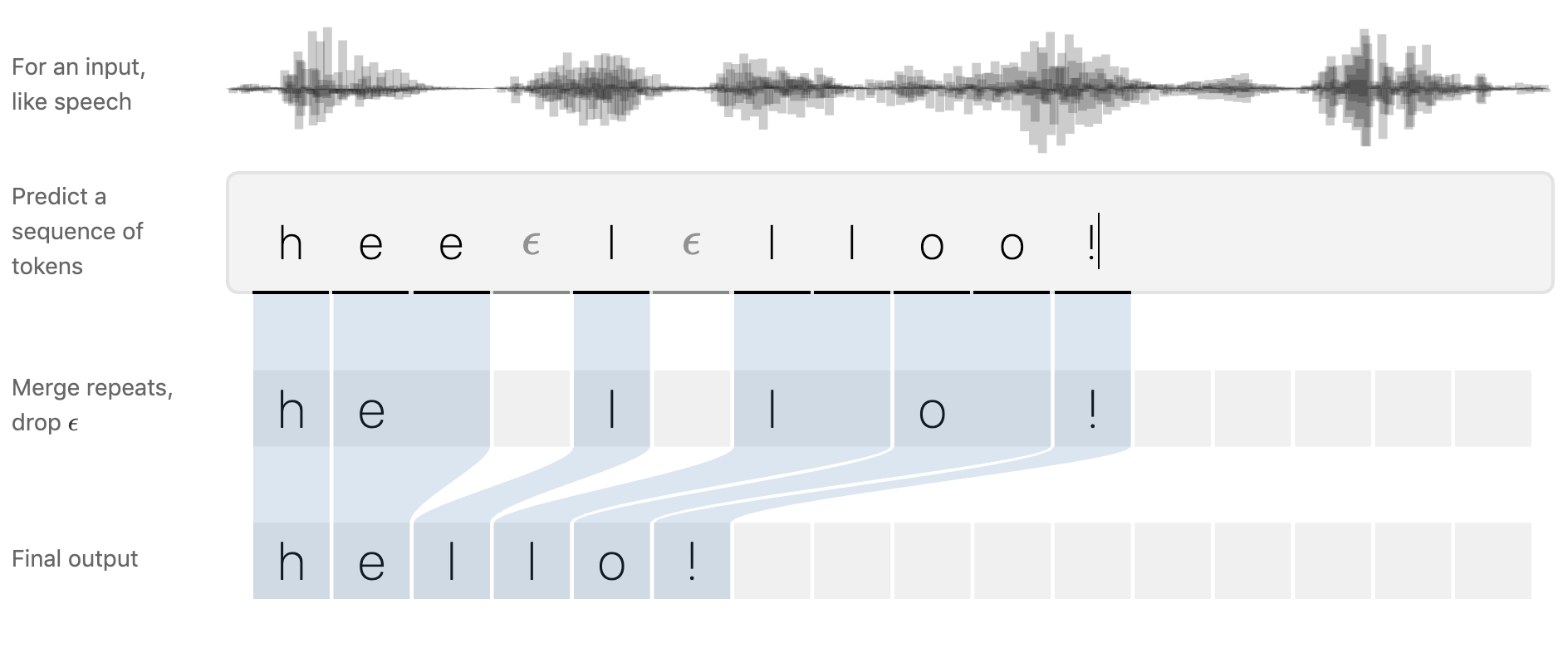
그리고 output은 이렇게 생겼다.
음성데이터니까 중간에 공백이 생길 수 있지만, 우리가 원하는 건 텍스트 추출이다.
텍스트만 뽑아내기 위해 후처리를 통해서 정제하고 공백을 뽑아버린다.
Encoder를 쌓고 그 위에 CTC 만 쌓으면 모델 구성이 가능해진다는 장점
그러나 정확한 alignment는 어렵고 decoder가 있어야 성능이 더 올라간다고 한다.
[LAS]
크게 Listener 와 speller로 나뉜다.
Listener는 인코더, speller는 디코더
speller는 인코더와 상관없이 12 to 12 를 예측함
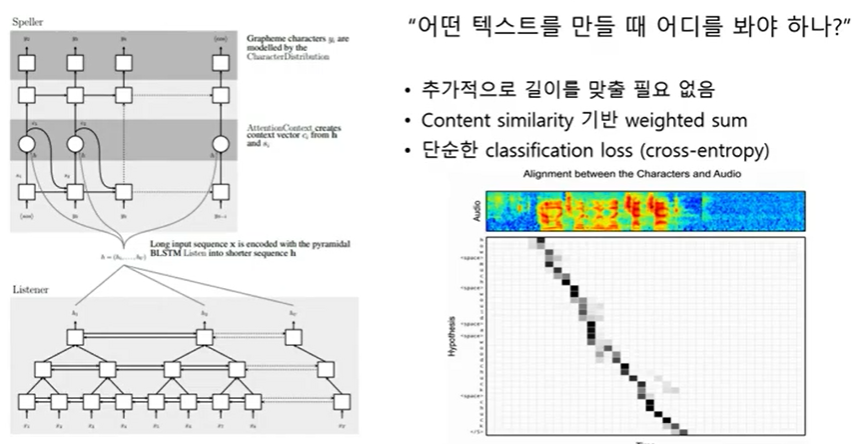
attention을 이용해서 Listner에서 추출한 1000개의 feature 중 무엇을 봐야할지 계산함
[RNN-T]
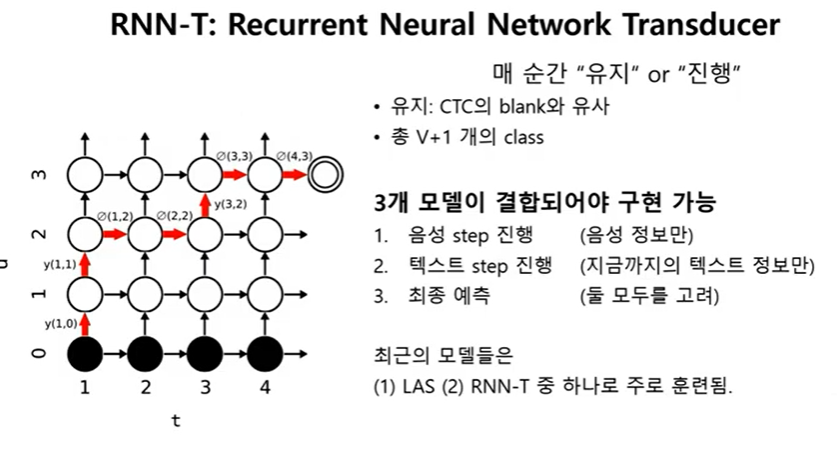
CTC와 유사함
그러나 blank를 통해서 길이를 맞춰주지는 않음
매 순간마다 음성을 진행하면서 (1000개를 하나씩 보면서) 다음 캐릭터로 넘어갈지, 머무를지를 결정함
각 모델의 차이를 보면 이렇게 됨
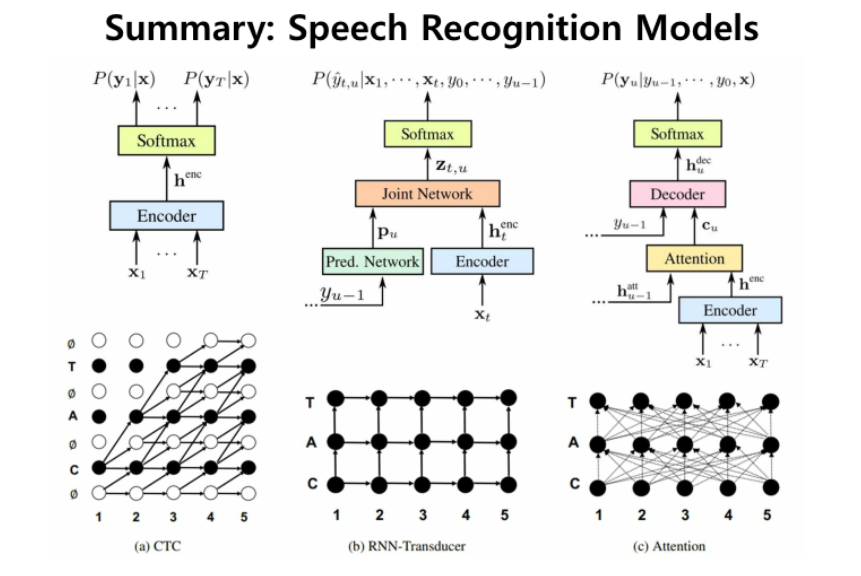
요즘은 CTC 보다는 LAS나 RNN-T 를 많이 쓴다고 함
CTC는 인코더만 LAS는 인코더, 디코더 RNN-T는 인코더, joint network, transducer network 가 필요
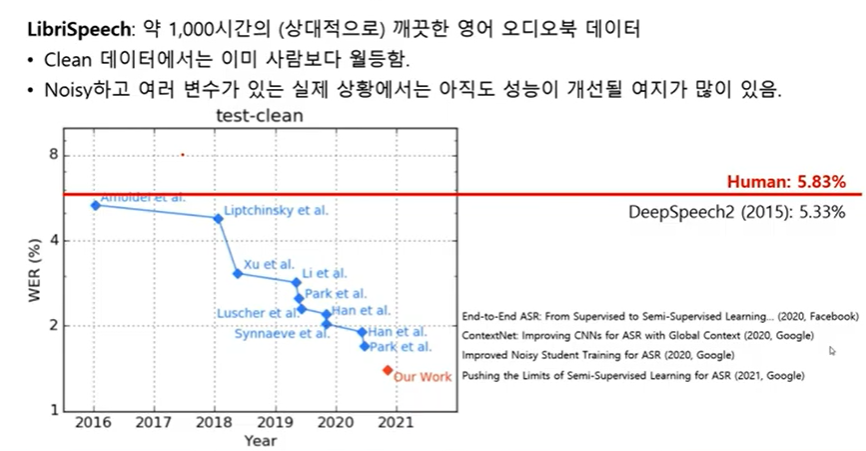
CV의 Imagenet 과 같은 위치의 음성 데이터 셋에서 활약하는 딥러닝 모델의 performance
'딥러닝 > 기타 리뷰' 카테고리의 다른 글
| [음성데이터] 음성데이터 개괄2 (0) | 2022.07.18 |
|---|---|
| [Optimizer]AdamW (0) | 2022.02.10 |
| [의료데이터] 단백질 구조 예측 (0) | 2021.11.24 |
| [GNN] GCN (0) | 2021.11.23 |
| [의료이미지 분석]Introduction to medical image analysis (0) | 2021.09.22 |




댓글